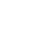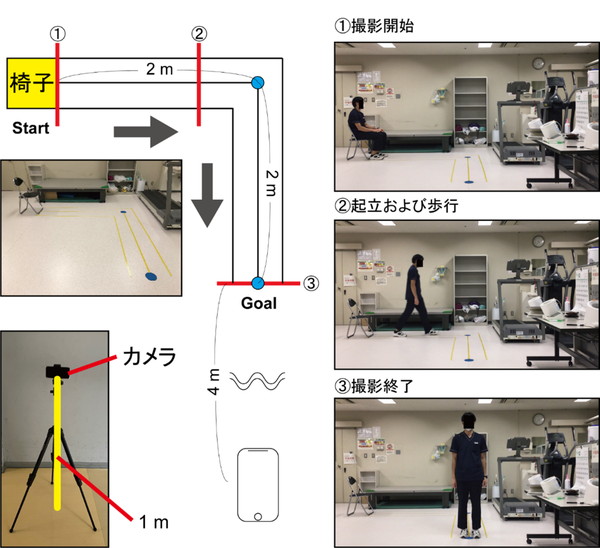
これまでの技術では考えられなかった「低解像度画像から高解像度画像を予測する」技術をGoogle Brainが発表しています。この技術の精度が向上すると、さまざまな分野での画期的な応用が期待されます。
機械学習のアルゴリズムや技術を研究しているGoogle Brainが開発した新しい技術は「Pixel Rercursive Super Resolution」というもの。

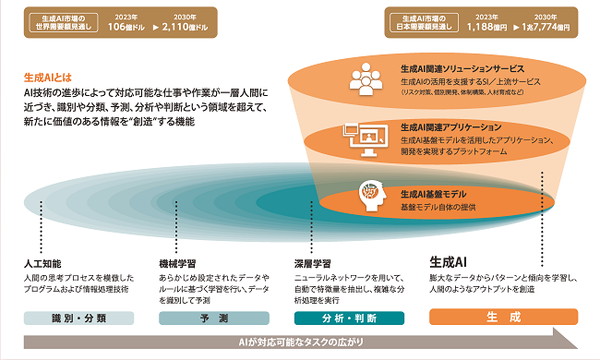
上の画像の左端は「8×8」ピクセルの画像ですが、この低解像度の画像から予測して作成されたのが、中央の画像です。実はこの8×8ピクセルの画像は、右端の画像の分解能を落としたものでした。
どうでしょうか。元の画像と比べてみると確かに完全には再現できたと言えませんが、まったく何かわからなかった左端の画像から16倍に解像度を上げて予測したと考えると、かなり精度は高いといえるのではないでしょうか。
Pixel Rercursive Super Resolution技術が予測できるのは、人の顔だけではありません。

上の画像の左端が低解像度の画像で、右側にある4つの画像が予測された画像です。このように、室内の画像なども予測して作り上げることができます。
低解像度の画像には、そもそもそれ以外の情報は含まれていません。では、いったいどのようにして元の高解像度画像をつくっているのでしょうか。
Google Brainが開発したこの技術では、「conditioning network」と「prior network」という2つのニューラルネットワークを使って画像予測を行っているという。
conditioning networkではまず、8×8ピクセルのソース画像を高解像度画像にマッピングします。このとき、さまざまな高解像度画像を8×8ピクセルにまで解像度を落とした画像が参考になります。これらの画像にソース画像が適合するかどうかを見ることで、マッピングしていきます。
低解像度のソース画像を高解像度にマッピングしたのちに、足りない部分の情報を「prior network」で追加していきます。この画像の補完作業には、「PixelCNN」が使われます。
prior networkでは、非常に多くの高解像度画像の情報が組み入れられています。低解像度のソース画像をスケールアップしたとき、画像として足りない部分のピクセルは、これらの大量の画像データを使って補われるというわけです。
Google Brainが開発したsuper-resolution技術は、この先も驚くほどのスピードで精度を上げていくと予想されます。
この技術はどのような分野で応用されるでしょうか。現実的な問題として最も大きなメリットが得られるのは、防犯カメラで撮影された映像の高解像度化ではないでしょうか。
近年はビデオカメラのデジタル化もあって、非常に解像度の高い映像が得られています。しかし、重要な対象物(犯罪の容疑者など)が小さい場合などは、より大きく引き伸ばす必要が出てきます。
これまでの技術では、引き伸ばされた映像をより見やすく画像調整することはあっても、より高解像度の映像に作り直すことは不可能でした。
このGoogle Brainが開発した高解像度画像の予測技術を使うと、小さくしか映っていない犯人の顔を引き伸ばして鮮明な映像にすることが可能になってきます。PixelCNN