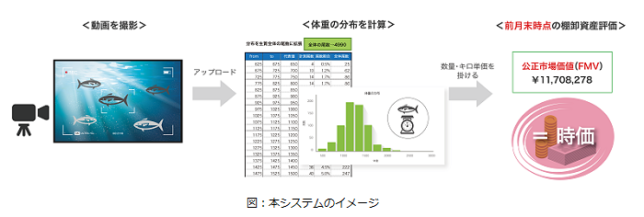
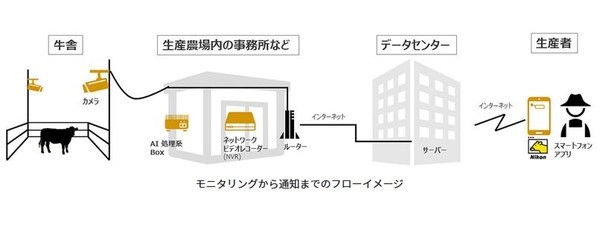
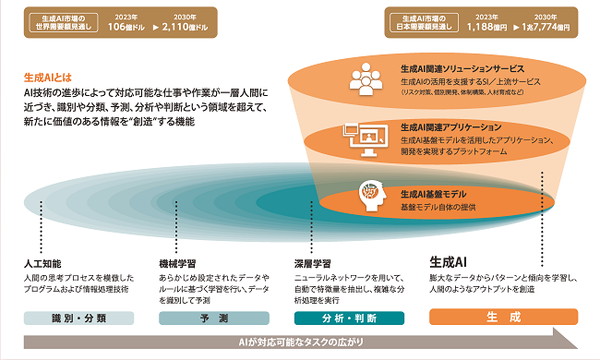
人工知能は人間と同等もしくはそれ以上の能力を発揮するために、膨大な量のデータを処理する必要があります。近年の技術発展によって処理能力は大きな進歩を遂げたとしても、AIを機能させるために必要な処理量はずば抜けています。
世界最高の検索システムを運用しているグーグルは、大きなデータセンターを世界に15カ所も所有。これらのデータ処理能力は間違いなく世界ナンバーワンだと思われますが、この能力をもってしても、AIのシステムを運用するには足りなかったようです。
グーグルがアンドロイド携帯に音声認識機能を新たに搭載したとき、現行の技術では2倍のデータセンターを構築する必要があったという。
そこで、グーグルは既存の技術でセンターの数を増やすことよりも、新たにディープラーニング専用のチップ「Tensor Processing Unit(TPU)」を開発しました。
一般的に、人工知能を学習する際にはほとんどの企業はGPUを使用します。GPUはゲームのグラフィックスなどで使われるチップで、ディープラーニングのための計算にも向いているといいます。
しかし、グーグルは既存のチップではなく、人工知能専用のチップを開発することを選択しました。
専用チップであるTPUの開発は2014年から始まりました。その後、2015年春には利用を開始しており、囲碁AIの「AlphaGo」でも使用していたそうです。
グーグルはなぜ自前のチップを開発することにしたのでしょうか。それは、「ムーアの法則」が成り立たなくなったためだとしています。
ムーアの法則とは、インテル社の創業者のひとり、ゴードン・ムーアが1965年に提唱した法則で、集積回路上のトランジスター数が1年半から2年ごとに倍になること。
つまり、当時はハードウェアが急速に進歩を続けていたものの、現在ではソフトの進化にハードの進化が追いつかなくなってしまった、というわけです。
これからはCPUの性能の向上が見込めないため、プロセッサをソフトに特化させていく必要があるとして、AI専用のチップを開発する道を選びました。
TPUは、ある特定のタスクを実行するためだけに基礎からつくられたチップ「ASIC(Application Specific Integrated Circuit、特定用途向けIC)」です。TPUの消費電力あたりの性能はGPUなどと比べて10倍あります。
なぜそのような高性能を達成できるかというと、「浮動小数点演算の精度を抑える」ことで、計算に必要なトランジスターを減らしているからだとしています。
ニューラルネットワーク専用に設計していることから、似たような技術でつくられた汎用のチップと比べるとプログラムを15~30倍も速く実行することが可能だとのこと。
また、このチップは画像認識や音声認識など、さまざまなニューラルネットワークに使うことができます。
IT業界の巨人であるグーグルは、自社のサービスを効率よく運用するために自前のチップまでも開発しました。ちなみに、開発したチップを社外に向けて販売する予定は無いそうです。